
Die Herausforderung
Für Kund:innen sind Verfügbarkeit und Sicherheit ihrer Anwendungen und Infrastrukturen von höchster Bedeutung.
Mit dieser Case Study zeigen wir, wie wir bei PCG mit Hilfe von Monitoring-Lösungen wie Datadog die Verfügbarkeit und Datensicherheit unserer Kund:innen optimieren – für mehr Zufriedenheit und eine starke Beziehung zwischen PCG und unseren Kund:innen.
Verfügbarkeit
Eine Schwachstelle der Anwendungen unserer Kund:innen sind potenzielle Ausfallzeiten, die durch Verfügbarkeitsprobleme von EC2-Instanzen oder Anwendungen entstehen – zum Beispiel durch DoS-Angriffe.
Anfang Oktober, an einem Samstag um 02:23 Uhr, wurde bei einem konkreten Vorfall genau diese Schwachstelle zum Problem. Es kam zu einem Ausfall von Confluence, der Bereitschaftsdienst der PCG wurde automatisiert hinzugezogen.
Sicherheit
Der Kunde ist auch sehr interessiert an Sicherheitsfragen im Zusammenhang mit Schwachstellen in Atlassian-Anwendungen und dem Flatcar-Betriebssystem. CVEs auf der Anwendungs- oder Betriebssystemebene können zu Sicherheitslücken führen.
Im Juni 2022 ging es vor allem um eine kritische Sicherheitslücke – eine Zero Day RCE-Schwachstelle (CVE-2022-26134![]() ) – in Atlassian Confluence-(Server and Data Center)-Anwendungen. Das zog unsere Aufmerksamkeit auf sich, und unser reaktionsschnelles internes Schwachstellenmanagement-Team, das mehrere Kanäle engmaschig auf solche Schwachstellenmeldungen überprüft, trat zügig in Aktion.
) – in Atlassian Confluence-(Server and Data Center)-Anwendungen. Das zog unsere Aufmerksamkeit auf sich, und unser reaktionsschnelles internes Schwachstellenmanagement-Team, das mehrere Kanäle engmaschig auf solche Schwachstellenmeldungen überprüft, trat zügig in Aktion.
Die Lösung
Um ein stabiles System zu gewährleisten, haben wir für unsere Kund:innen einen Bereitschaftsdienst eingerichtet, der bei Zwischenfällen rund um die Uhr Unterstützung bietet. Wir sorgen für eine kontinuierliche 24/7-Überwachung unserer Infrastruktur und konzentrieren uns dabei besonders auf EC2-Instanzmetriken wie CPU-Nutzung, Festplattennutzung, verfügbarer Arbeitsspeicher und andere wichtige Metriken. Diese Überwachung wird durch unsere speziellen Überwachungstools, Datadog und New Relic, unterstützt.
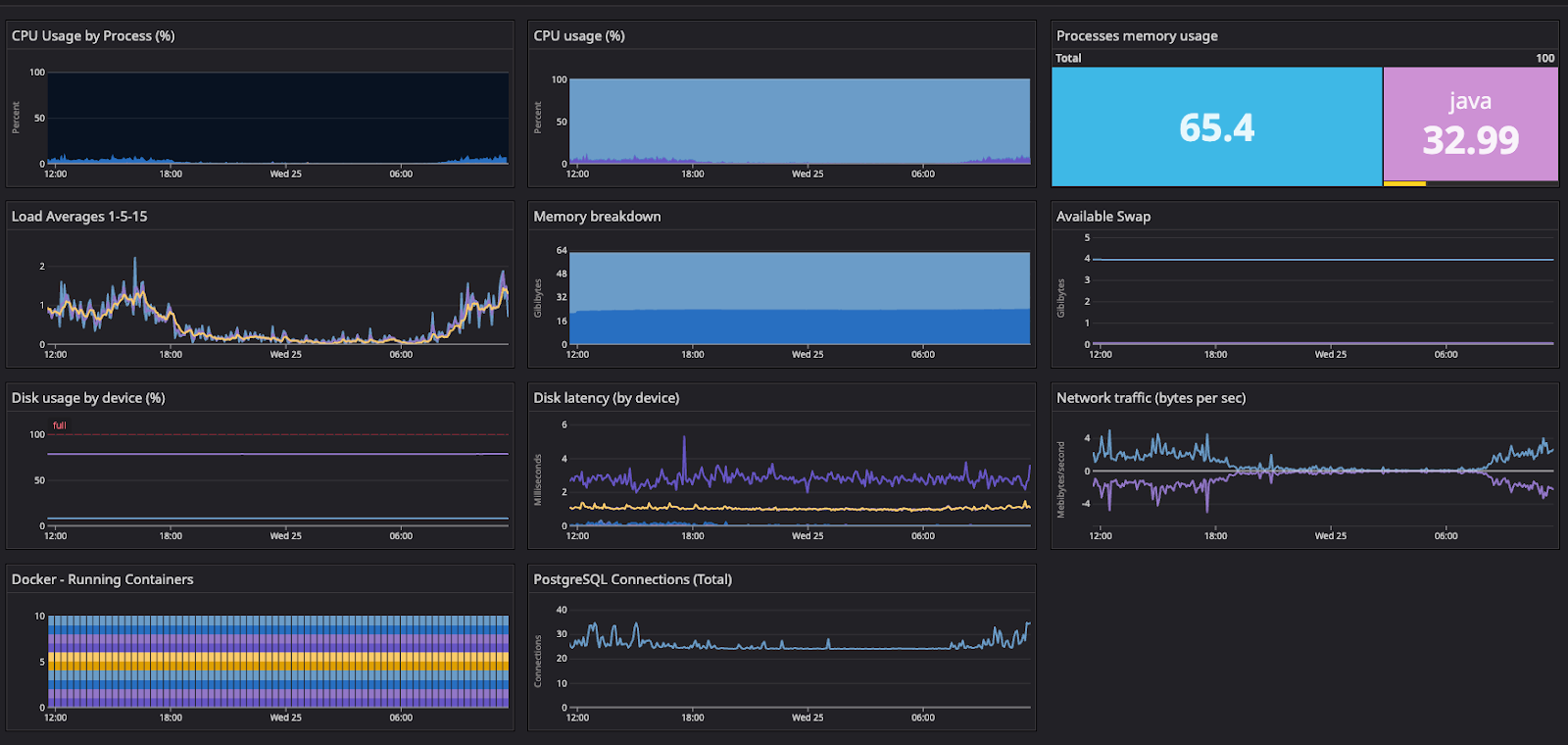
Darüber hinaus überwachen wir bestimmte Metriken im Zusammenhang mit den Atlassian-Java-Anwendungen des Kunden engmaschig – einschließlich Swapping, Garbage Collection und Heap-Zuweisungen. Sobald Probleme auftreten, lösen unsere Datadog-Monitore sofort Warnmeldungen aus, die direkt in unsere Messaging-Plattform Slack und unseren Operations-Tool OpsGenie integriert sind. Diese Verzahnung stellt sicher, dass die Person im Bereitschaftsdienst umgehend die notwendigen Benachrichtigungen erhält, wie unten dargestellt:
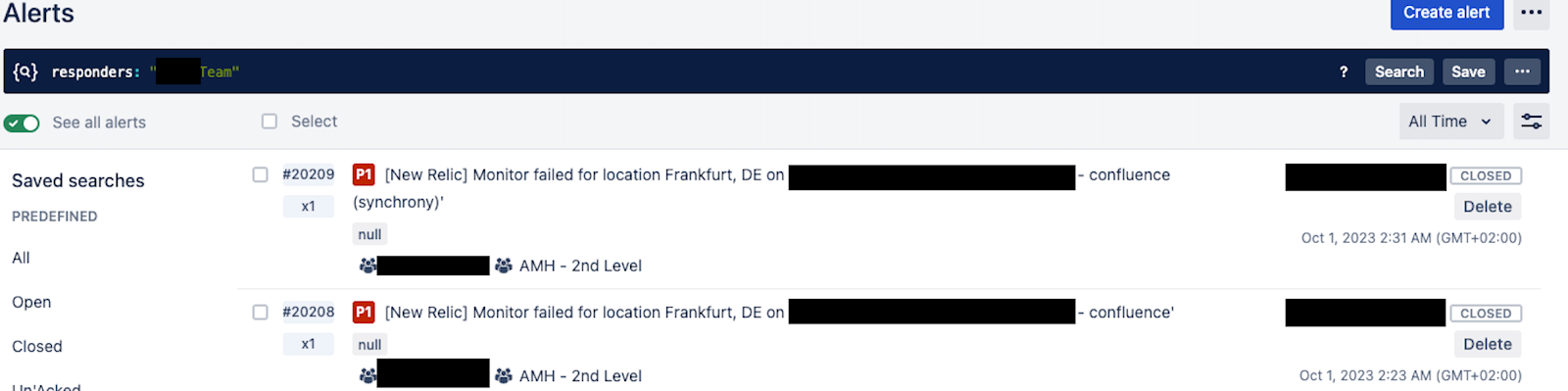
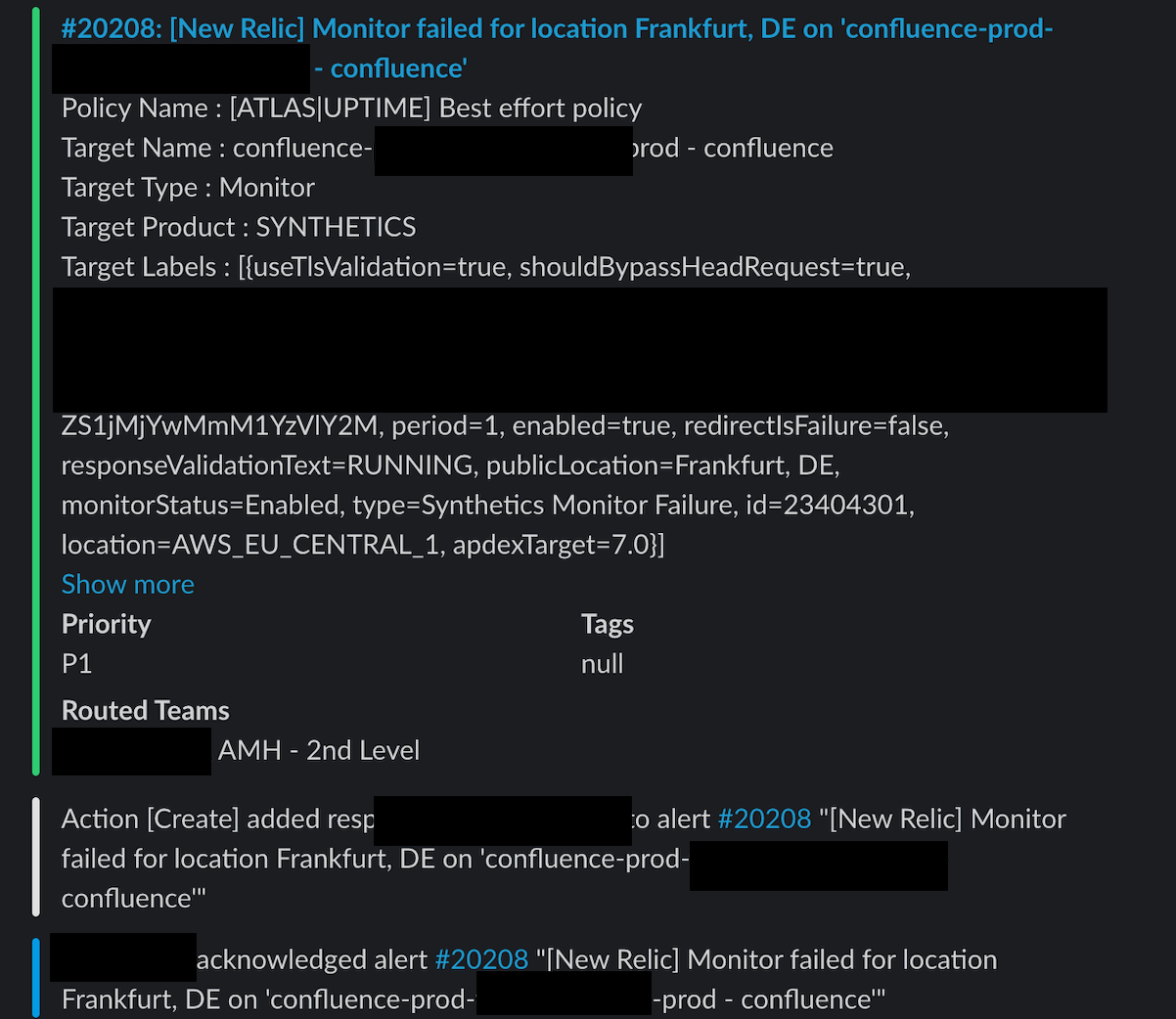
Bei dem oben beschriebenen Vorfall konnte durch einen schnellen Neustart eine temporäre Lösung gefunden werden, die Confluence nach 8 Minuten wieder in den Normalbetrieb versetzte. Die fortlaufende Überwachung ließ erkennen, dass auf der Confluence-Instanz die CPU-Auslastung kontinuierlich angestiegen war. Dies war letztlich der Auslöser für den Ausfall. Nach eingehender Protokollanalyse stellte sich heraus, dass durch eine große Zahl von Anfragen eines Nutzers High-Load-Aufgaben – insbesondere PDF-Exporte – über den Proxy an Confluence ausgelöst wurden:
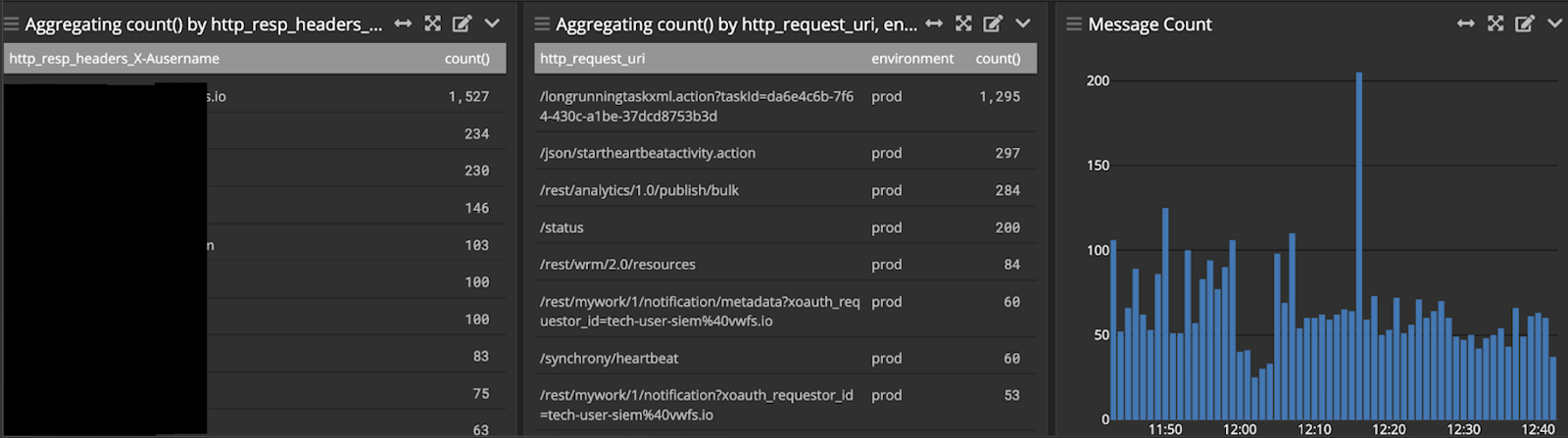
Obwohl sowohl der Benutzer als auch der Kunde per E-Mail und über ein Service-Desk-Ticket benachrichtigt wurden, dauerten die Anfragen noch mehrere Stunden nach dem Vorfall an.
Um weitere Ausfälle zu verhindern, wurde der Benutzer anschließend gesperrt. Damit waren die Leistungsprobleme wirksam behoben.
Sicherheitslösung
Unser Team überwacht kontinuierlich das Flatcar-Betriebssystem sowie spezifische CVEs von Atlassian-Anwendungen und kümmert sich umgehend um alle erkannten Probleme.
Die Sicherheitsüberwachung wird über verschiedene Ressourcen verwaltet – unter anderem durch Meldungen von Atlassian über anwendungsspezifische CVEs.

Darüber hinaus nutzen wir secalerts.co![]() , um Informationen über CVEs zu erhalten, die sich auf von uns eingesetzte Software wie zum Beispiel flatcar auswirken. secalerts ist in unser Jira und Slack integriert und generiert Tickets und Warnungen innerhalb unseres Netzwerks.
, um Informationen über CVEs zu erhalten, die sich auf von uns eingesetzte Software wie zum Beispiel flatcar auswirken. secalerts ist in unser Jira und Slack integriert und generiert Tickets und Warnungen innerhalb unseres Netzwerks.
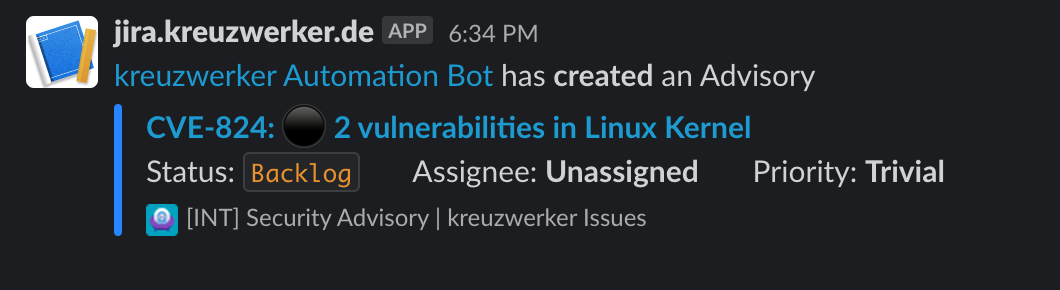
Wir werten diese Warnungen sorgfältig aus und evaluieren die möglichen Auswirkungen auf unsere Kund:innen. In Situationen mit erhöhtem Risiko informieren wir unsere Kund:innen proaktiv und geben ihnen detaillierte Einblicke in spezifische Probleme, potenzielle Lösungen und verfügbare Workarounds, um Risiken so weit wie möglich zu minimieren. Bei kritischen Ereignissen führen wir manchmal außerhalb der Geschäftszeiten System-Patches durch, auch wenn der Kunde zuvor keine ausdrückliche Zustimmung erteilt hat. Dabei hat für uns die Sicherheit der Systeme unserer Kund:innen oberste Priorität.
Zusätzlich zu den beiden oben genannten Überwachungslösungen verwenden wir Amazon Inspector![]() , um unsere Container-Images und die entsprechenden Bibliotheken auf Schwachstellen zu überprüfen:
, um unsere Container-Images und die entsprechenden Bibliotheken auf Schwachstellen zu überprüfen:
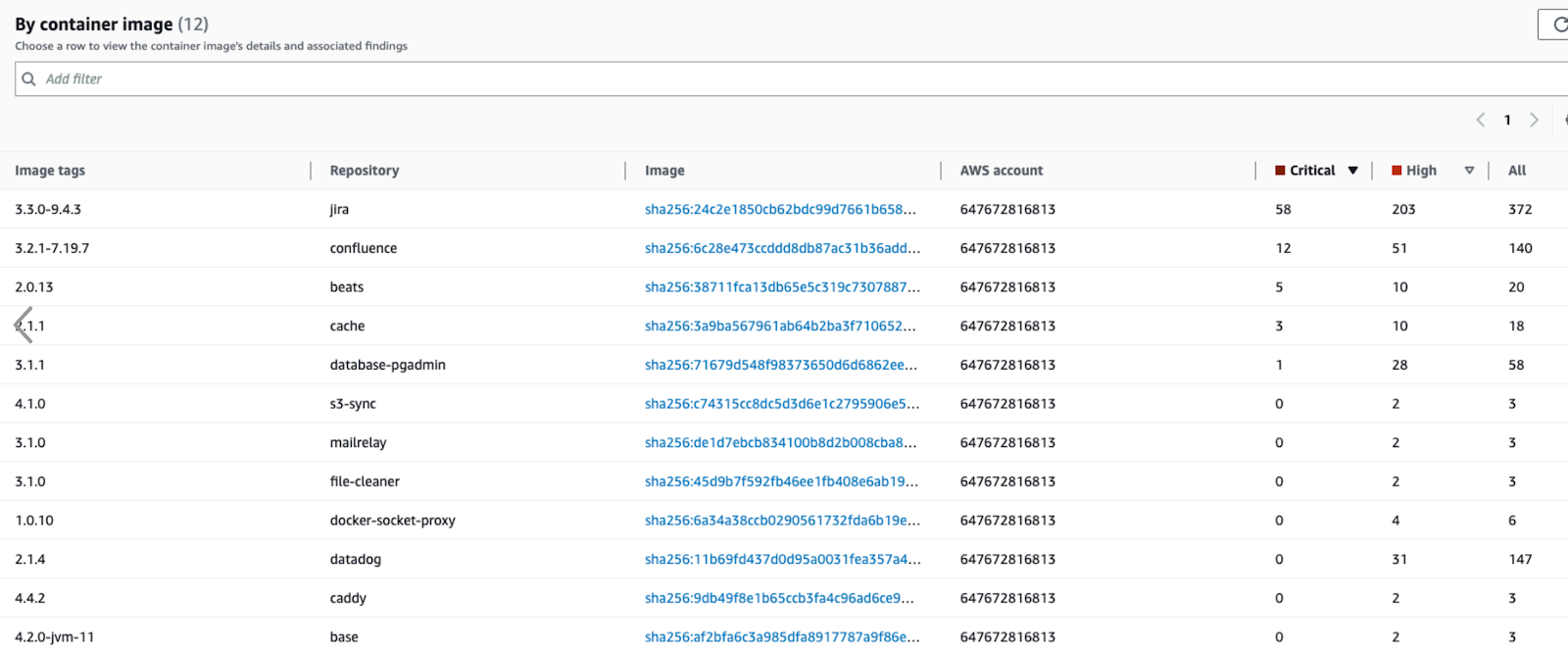
Wenn wir diese korrigieren können, patchen wir die Bibliotheken und stellen die gepatchten Container so schnell wie möglich bereit. Im Screenshot unten ist ein Beispiel zu sehen, wie wir mehrere kritische und gravierende Fehler in unserem PostgreSQL-Container behoben haben:
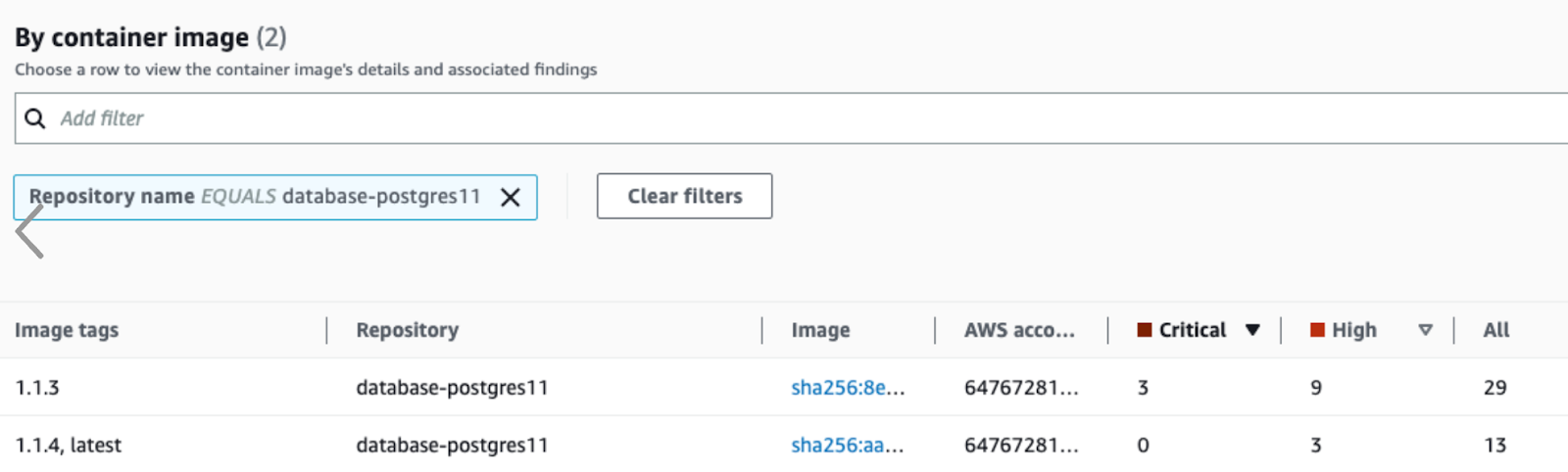
Bei dem erwähnten Vorfall haben wir unsere technischen Ansprechpartner auf Kundenseite umgehend benachrichtigt und die empfohlenen Abhilfemaßnahmen umgesetzt. Dazu gehörte auch das Blockieren von Anfragen, die bestimmten URL-Mustern entsprechen. Außerdem setzten wir IP-Whitelisting durch, um den Zugriff auf Instanzen zu beschränken, wo dies möglich war. Sobald Atlassian die Patch-Version freigegeben hatte, wendeten wir den automatisierten Bereitstellungsprozess an und sorgten dafür, dass die Korrektur innerhalb weniger Stunden nahtlos in das System des Kunden integriert wurde.
Resultate und Vorteile
Der Kunde unterstützte anschließend unseren Prozess und klärte, dass die Anfragen des Nutzers unbeabsichtigt und automatisiert erfolgt waren.
Die kontinuierliche Rund-um-die-Uhr-Überwachung der Infrastruktur und der Anwendungen des Kunden hat also zu einem dauerhaft stabilen System beigetragen, wie aus dem später erstellten Uptime-Report hervorgeht:
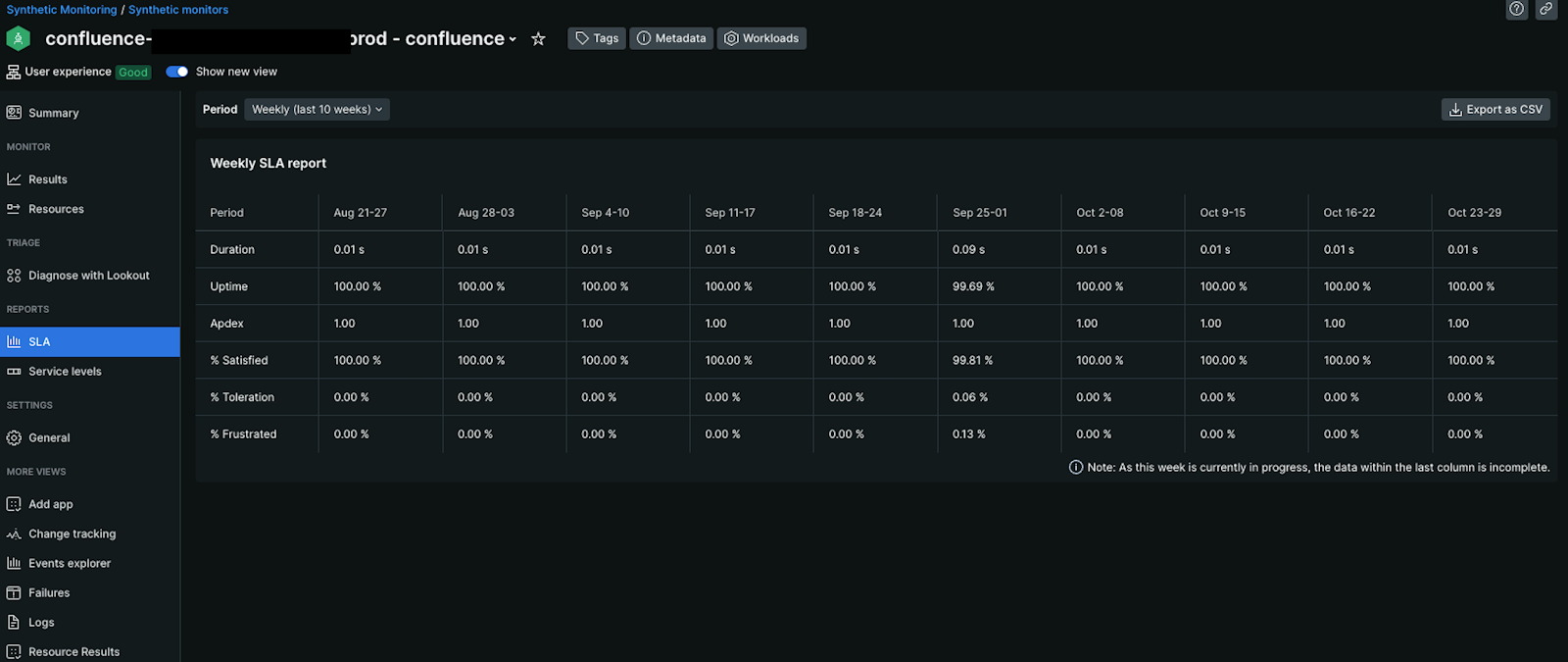
Die oberen drei Sicherheitsverfahren garantieren, dass die Software, die auf den EC2-Instanzen der Kund:innen läuft, gepatcht und sicher ist. So sind Kundendaten bestmöglich vor potenziellen Angriffen geschützt.
Über PCG
Die Public Cloud Group (PCG) unterstützt Unternehmen bei ihrer digitalen Transformation durch den Einsatz von Public Cloud-Lösungen.
Mit einem Portfolio, das darauf ausgerichtet ist, Unternehmen aller Größe auf ihrer Cloud Journey zu begleiten, sowie der Kompetenz von zahlreichen zertifizierten Expert:innen, mit denen Kunden und Partner gerne zusammenarbeiten, positioniert sich PCG als verlässlicher und vertrauenswürdiger Partner der Hyperscaler.
Als erfahrener Partner der drei relevanten Hyperscaler (Amazon Web Services (AWS), Google Cloud und Microsoft Cloud) hält PCG die höchsten Auszeichnungen der jeweiligen Anbieter und berät Sie als unsere Kunden in Ihrer Cloud Journey unabhängig.