
What is RAG?
Retrieval Augmented Generation (RAG) is an innovative technique in natural language processing that enhances text generation by blending insights from private or proprietary data sources. It combines a retrieval model, designed to navigate large data sets or knowledge bases, with a generation model, typically a Large Language Model (LLM), which processes and generates coherent text.
RAG improves search accuracy by integrating contextual information from additional data sources, enriching the LLM's knowledge without additional training. Unlike traditional methods that require model retraining, RAG optimizes language model output without lengthy iterations.
By leveraging diverse data sources such as internet data, proprietary business records, or internal documents, RAG simplifies tasks like answering questions and creating content. Its capability to access external information empowers generative AI to provide more accurate, contextually relevant responses. RAG implementations typically employ search and retrieval techniques, such as vector or semantic search methods, to tailor responses to user intents and deliver the most relevant results.
How does RAG work?
The figure shows a typical RAG pipeline. The whole process is divided into two parts:
Retrieval
- The process starts with inputting a query, which can be a user question or any textual input that requires a detailed response.
- The question is transformed into a vector in a high-dimensional space and is compared with the vectors which are stored in a knowledge database.
- The retrieval model ranks the vectors in the knowledge database based on their similarity to the original question. Documents or text passages with the highest scores are selected for further processing. This is commonly referred to as semantic search.
- These retrieved pieces of information now serve as a reference source for all facts and contextual data the model needs.
Generation
- In the second part, a prompt containing instructions for generating a response, along with the context and the original question, is sent to an LLM.
- The LLM generates a response based on the prompt.
- These responses are generally more accurate and contextually meaningful because they have been enriched with supplementary information provided by the retrieval model. This capability holds particular significance in specialized domains where publicly accessible internet data falls short.
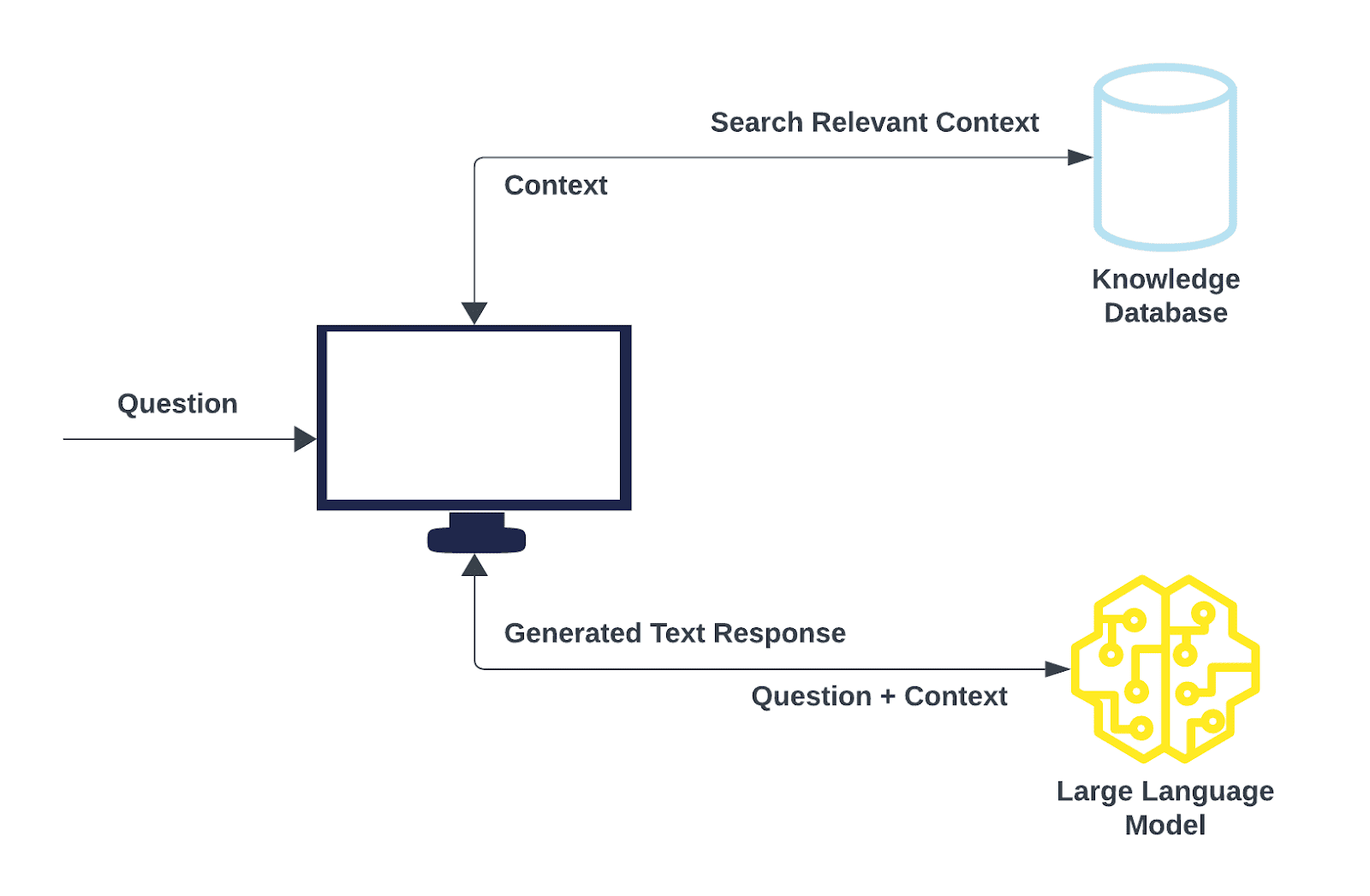
Figure: A typical RAG pipeline
What are the benefits of RAG?
- Up-to-date Information: RAG keeps the model up-to-date with the latest and most relevant information by regularly updating external references. This ensures that generated responses take into account the most recent data pertinent to user queries.
- Cost-effectiveness: RAG provides a cost-effective solution that requires less computational power and storage compared to independently training large language models. It eliminates the need for creating and training custom models, saving both time and money.
- Enhanced Accuracy and Validation: RAG can cite external sources to support and validate responses, providing users with additional references for verification. This feature helps to bolster the credibility and accuracy of the generated responses.
What are the applications of RAG?
- Improved Customer Experiences: RAG introduces a paradigm shift in how companies interact with their customers, providing unparalleled opportunities to improve the experience. By integrating RAG into their systems, companies can ensure that customer requests are met with accurate, relevant, and timely responses. Whether it's addressing product inquiries, resolving issues, or providing assistance, RAG enables businesses to deliver seamless and personalized experiences that foster loyalty and trust.
- Chatbots and Virtual Assistants: Chatbots and virtual assistants have become indispensable tools for businesses looking to streamline customer interactions. With RAG, these AI-powered agents transcend mere scripted responses, tapping into vast knowledge repositories to deliver contextually rich and tailored interactions. By leveraging RAG's capabilities, chatbots and virtual assistants can better understand user intent, anticipate needs, and provide nuanced responses, thereby elevating the quality of customer engagement to unprecedented levels.
- Personalization: In today's era of hyper-personalization, customers expect interactions to be tailored to their preferences and behaviors. RAG plays a pivotal role in enabling this level of personalization by dynamically adapting responses based on individual context and history. Whether recommending products, offering advice, or providing support, RAG ensures that each interaction feels tailored and relevant to the customer's unique needs and preferences. This personalized approach not only improves customer satisfaction, but it also drives customer retention and loyalty, ultimately driving business success.
In short, RAG combines retrieval and generation models for powerful text creation. It leverages external knowledge for accurate, relevant responses, and personalizes interactions. This cost-effective technique offers a big leap in AI interaction. Our experts at Public Cloud Group can assist businesses in identifying and implementing RAG for their specific AI use cases, ensuring they harness the full potential of this innovative technology.